persian
persian") English (UK)
English (UK) 
تشخیص زبان یک متن، یکی از اولین گام ها به سوی متن کاوی است. مخصوصا در فضای بزرگ سایبر که تنوع بسیار زیادی از داده ها وجود دارد. حتی ممکن است گاهی در اسناد سازمانی هم با تنوع متفاوتی از زبان ها در اسناد مواجه شویم. در بیشتر موارد مخصوصا اگر رنج تنوع زبان ها در متون زیاد باشد، حتی قبل از تجزیه کردن (Pars) و ایندکس کردن فایل های متنی ترجیح داده میشود که با یکی از روش های تشخیص زبان در متون، نوع زبان شناسایی شود. چرا که از هزینه پارس کردن بی مورد متون که برابر با زبان مورد نظر ما نیست جلوگیری شود. تا کنون ایده های مختلفی برای تشخیص زبان در متن ارائه شده. که در این مبحث دو مورد از روش های تشخیص زبان مورد بررسی قرار میگیرد.
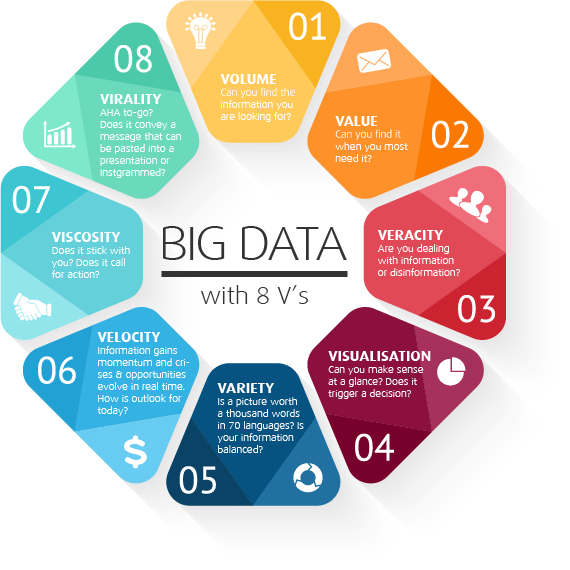
- روش شناسایی الگوی زبان بر اساس شباهت ها
- روش اکتشاف از روی عناصر داخل فایل متنی یا از متا دیتا ها
روش شناسایی الگوی زبان بر اساس شباهت ها
از دیگر روش های تشخیص زبان میتوان به روش های شناسایی الگو اشاره نمود. در این روش برای تشخیص زبان صفحات وب، متن موجود در آنها مورد تحلیل قرار میگیرد. روند کلی روشهای موجود در این حوزه به این ترتیب است که ابتدا با استفاده از مجموعهای از متون متعلق به یک زبان خاص یک مدل بازنمایی از آن زبان ساخته میشود و این کار به ازای مجموعه زبانهایی که سیستم قصد تشخیص آنها را دارد، تکرار میشود. مشابه با پردازش صورت گرفته بر سندهای موجود در مجموعه دادهها، پردازشی بر روی هر سند HTML ورودی به سیستم که قصد تشخیص زبان آن را داریم، انجام میگیرد و یک بازنمایی از سند جاری به دست میآید. بر اساس یک معیار شباهت، میزان تشابه بازنماییهای زبانهای موجود با بازنمایی سند جاری محاسبه میشود. زبانی که بیشترین تشابه را با بازنمایی سند جاری داشته باشد و مقدار آن از یک آستانهی از پیش تعیین شده بیشتر باشد، به عنوان زبان سند در نظر گرفته میشود.
به عنوان نمونه بازنمایی زبانها و سندهای HTML ورودی میتواند با استفاده از مدل فضای بردار VSM یا ( Vector Space Model) انجام شود. این فضا نیز میتواند بر اساس مجموعهای از کلمات کوچک و پرتکرار یک زبان، پسوندها، پیشوندها و یا مجموعهای از n-gramهای پرتکرار یک زبان شکل بگیرد. هر یک از کلمات، پسوندها، پیشوندها یا n-gramها یکی از ابعاد فضای ویژگی را تشکیل میدهند. استفاده از کلمات کوچک به عنوان ابعاد فضای ویژگی میتواند برای تشخیص زبان صفحات بزرگ مورد استفاده قرار گیرد. مقدار هر یک از ابعاد نیز میتواند بر اساس بسامد ویژگی متناظر با آن بعد در بردار بازنمایی زبان یا سند تعیین گردد.
میزان شباهت بردار بازنمایی یک سند با بردار بازنمایی هر یک از زبانها میتواند با استفاده از معیار شباهت کسینوس، فاصله اقلیدسی یا هر معیار فاصلهی دیگری محاسبه شود. در ادامه روشی را تشریح میکنیم که بسیاری از ابزارها برای شناسایی زبان متون از آن استفاده نمودهاند.
-
TextCat:دستهبندی متون مبتنی برn-gramها
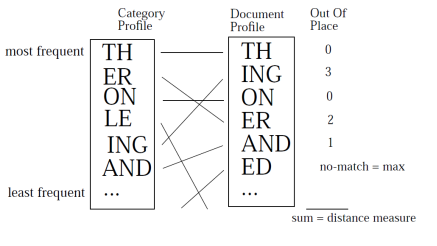
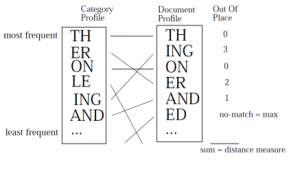
روش ارائه شده که TextCat نام دارد، از مجموعهای از n-gramها که بیشترین بسامد را در مجموعهای از متون متعلق به یک زبان داشتهاند، برای بازنمایی یک زبان استفاده میکند. برای شناسایی زبان هر متن وارد شده به سیستم ابتدا مجموعه n-gramهای پربسامد آن استخراج میشود سپس با استفاده از روش سادهای به نام «خارج از جایگاه» (Out-of-place) فاصله بین بازنمایی زبانها و بازنمایی متن ورودی محاسبه میشود. این روش ابتدا n-gramهای زبان و متن را بر اساس بسامدشان مرتب میکند. سپس جایگاه هر یک از n-gramها را در زبان و سند با هم مقایسه و اختلاف آنها را محاسبه مینماید. اگر n-gramی در یکی از بازنماییها وجود داشته باشد و در دیگری واقع نشده باشد، حداکثر اختلاف فاصله برای این n-gram منظور میشود.
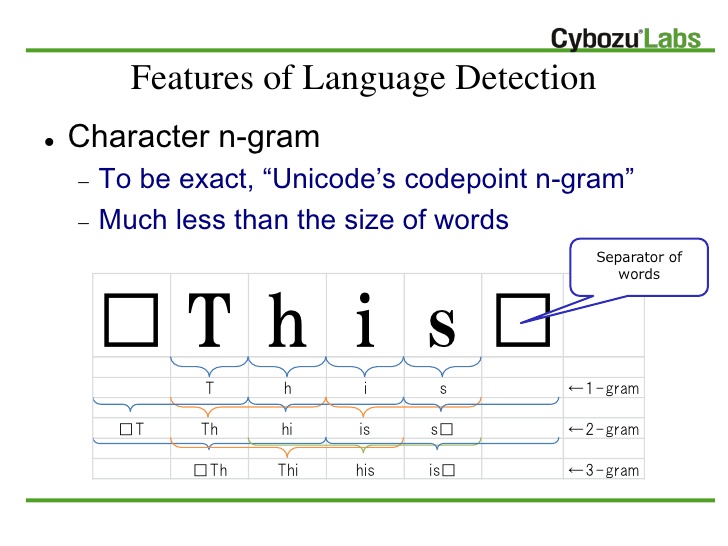
شکل پایین مثالی از محاسبه فاصله n-gramها برای بازنمایی یک زبان با بازنمایی یک سند را نشان میدهد. مثلا ING در بازنمایی زبان در جایگاه پنجم و در بازنمایی سند ورودی در جایگاه دوم قرار گرفته است بنابر این فاصلهی «خارج از جایگاه» آن برابر با ۳ خواهد بود.
در استفاده از n-gramها باید نکاتی را مد نظر قرار داد. مثلاً زبانهایی نظیر فارسی، عربی و اردو دارای n-gramهای شبیه به یکدیگر هستند که عدم توجه به این موضوع، می تواند منجر به تشخیص نادرست زبان یک واحد اطلاعاتی گردد. نحوه کدگذاری صفحه نیز در تشخیص زبان بر اساس n-gram اهمیت دارد. زیرا مثلاً اگر UTF-8 به عنوان Arabic در نظر گرفته شود، تشخیص زبان به کمک n-gram صحیح نخواهد بود.
اکتشاف از روی عناصر داخل فایل متنی یا از متا دیتا ها از روش های تشخیص زبان
در این تکنیک از روش های تشخیص زبان سعی میشود با استفاده از اطلاعات موجود در صفتهای برچسبهای (tag) یک سند مثلا یک صفحه وب زبان آن شناسایی شود. برچسبهایی مانند meta با صفتهایی نظیر
- http-equiv=”Content-Language”
- name=”dc.language”
- name=”Content-Language”
در شناسایی زبان قابل استفاده هستند. در استفاده از این برچسبها باید به نکاتی توجه داشت:
- ممکن است زبان صفحه متفاوت از زبان مشخص شده در برچسبها باشد. این در مورد صفحاتی غیر انگلیسی امری رایج است.
- ممکن است صفحه چند زبانه باشد.
در ذیل مثالهایی از برچسبهای HTML که می توانند برای شناسایی زبان استفاده شوند، آورده شده است:
- <meta http-equiv=”Content-Language” content=”en” />
- <meta name=”dc.language” content=”en” />
- <meta name=”dc.language” content=”de, fr, it” />
صفت های دیگری lang نیز در تشخیص زبان قابل استفاده هستند. در زمان استفاده از برچسبهای HTML باید به نکات گوناگونی توجه داشت. یکی دیگر از نکات این است که زبان صفحه در برچسبهای HTML به شکلهای گوناگونی ظاهر میشود. مثلاً برای زبان فارسی از نامهای «Persian» یا «per» استفاده میشود. این در حالی است که نمایش استاندارد زبان فارسی طبق کنسرسیوم وب به صورت «fa» است.
یکی دیگر از نکات این است که از طریق CSS و DOCTYPE نمیتوان زبان را صفحه را تشخیص داد. زیرا مثلاً در DOCTYPE زبان مشخص شده مرتبط با محتوای صفحه نیست و به شمای صفحه ارتباط دارد.
روش های تشخیص زبان فارسی
ابزارهای متنوعی و بسیاری برای تشخیص زبان متن وجود دارند، اما این تعداد کمی از این ابزارها قادر به تشخیص زبان فارسی هستند. ابزار کد باز تشخیصگر زبان متن Langdetect قادر به تشخیص ۵۲ زبان از جمله فارسی، عربی، اردو، روسی و انگلیسی میباشد. اساس کار این ابزار شکست کلمات بر اساس N-gram با سه مقدار متفاوت یک ، دو و سه gram است، سپس برای هر یک از شکستها ترکیبات مختلف حروف را درنظر گرفته و فرکانس پراکندگی آن ترکیب را در متن مورد نظر محاسبه میکند و یک هیستوگرام تهیه میکند سپس با مقایسهی این فرکانسها با هیستوگرامهای اصلی (که برای هر زبان هیستوگرامهای اصلی قبلاً از روی پیکرههای زبانی ساخته شدهاست، پیکرهی مورد استفاده در این ابزار سایت Wikipedia است)، زبان هر متن تشخیص داده میشود. دقت این ابزار برای زبان فارسی با استفاده از پیکرهی همشهری ۰٫۹۹۹۷% محاسبه شده است. تعداد حداقل کلمهی لازم برای تشخیص صحیح زبان یک متن در انگلیسی ۵ کلمه و در فارسی حدود ۸ کلمه برآورد شده است.
-------------------------------------
منبع : خانه بیگ دیتای ایران