persian
persian") English (UK)
English (UK) 
با ظهور وب ۲٫۰ و اینترنت اشیا، ردگیری همه نوع اطلاعات، خصوصاً جزئیات فعالیتهای کاربر و اطلاعات سنسورهای محیطی و حتی بیومتریک آنها، در طول زمان ممکن شدهاست. با اینحال، از آنجاییکه کارایی برای کاربردهایی که با حجم عظیم داده سروکار دارند الزامی است، تنها بخشی از توان بالقوه کلانداده با استفاده از رویکردهای سنتی دستهای قابل بهرهبرداری است، زیرا ارزش دادهها بهسرعت تنزل مییابد و تأخیر زیاد در بسیاری از کاربردها غیرقابلقبول است. در چندین سال گذشته، برخی از سیستمهای پردازش داده توزیع شده ظهور یافتهاند، که از رویکرد پردازش دستهای فاصله گرفتهاند و آیتمهای داده را به محض دریافت تحلیل میکنند و در نتیجه به اهمیت در حال رشد زمان و سرعت در تجزیه و تحلیل کلان داده توجه دارند. در این مقاله، جدیدترین شیوههای پردازش دادههای جریانی در تجزیه و تحلیل کلانداده با تأخیر کم را بازنگری خواهیم کرد و به صورت کیفی، محبوبترین رقیبان این حوزه، و به صورت خاص ابزارهای Apache Storm و لایههای انتزاعیاش Trident،آپاچی Samza، مولفه Spark Streaming و Apache Flink را مقایسه میکنیم. منطق زیرساختی مربوط به آنها را توصیف میکنیم، تضمینهای ارائه شده توسط آن را بیان، و درباره ملاحظاتی که در انتخاب یکی از آنها برای یک وظیفه خاص مواجه خواهیم شد، بحث خواهیم کرد.
مقدمه
به دلیل پیشرفتهای تکنولوژی و افزایش ارتباطات بین مردم و دستگاهها، میزان داده در دسترس برای شرکتهای اینترنتی، دولتها و سازمانهای دیگر به طور مداوم در حال رشد است. خصوصاً جهتگیری به سمت محتوای پویا و تولید شده توسط کاربران در اینترنت و حضور همهگیر تلفنهای هوشمند، گجتهای پوشیدنی و دیگر دستگاههای سیار، سبب فراوانی اطلاعاتی شده که تنها برای مدت کوتاهی ارزشمند هستند و در نتیجه باید بلافاصله پردازش شوند. شرکتهایی مانند آمازون و نتفلیکس خود را تا حد بسیار خوبی با این موضوع تطبیق دادهاند و فعالیت کاربران را تحتنظر دارند تا محصولات و خدمات پیشنهادی خود را برای هر کاربر بهینه سازند. توئیتر به صورت پیوسته به تجزیه و تحلیل احساسات میپردازد تا کاربران را در جریان موضوعات روز قرار دهد و حتی گوگل از پردازش دستهای استفاده میکند تا اینترنت را شاخصگذاری کند و تأخیر بازتاب مطالب جدید و بهروز شده وبسایتها را به حداقل برساند.
با این حال، ایده پردازش دادههای در حرکت، ایدهی جدید نیست: موتورهای پردازش رویداد پیچیده (CEP) مانند Aurora، Borealis یا Esper و سیستمهای مدیریت پایگاهداده با امکانات پرسوجوی پیوسته مانند Tapestry یا PipelineDB میتوانند تأخیر پردازشیای در حدود چند میلیثانیه فراهم کنند و معمولاً رابطهای سطحبالا و مشابه SQL و عملکردهای پیچیده پرسوجو، مانند عملگر پیوند را ارائه میدهند. اما استقرار معمول این سیستمها در ابعادی بیشتر از چند گره نخواهد بود و در تعداد بالا معمولا با چالشهای زیادی روبرو هستند. ابزارهایی که در این مقاله بررسی میکنیم، معمولاً مخصوص استقرار بر روی دهها، صدها و تا هزاران گره پردازشی طراحی شدهاند. شاید یکی از اصلیترین دستاورد این سیستمهای جدید، نظیر نگاشت/کاهش، انتزاع و تفکیک آن از مشکلات مقیاسپذیری است و در نتیجه، امکان توسعه، پیادهسازی و نگهداری این سیستمها با مقیاسپذیری بالا را ایجاد کردهاند.
تحلیل زمان واقعی: کلانداده در حرکت
برخلاف سیستمهای تحلیلی سنتی، که دادهها را جمعآوری و مرتبا حجم عظیم و ایستایی از دادهها را پردازش میکنند، سیستمهای تحلیلی جریانی از نگهداری دادهها به صورت ایستا اجتناب کرده و به محض دسترسی، آنها را پردازش میکنند، و در نتیجه هر آیتم داده، مدت زمان اندکی در خطلوله پردازش خواهد بود. معمولاً سیستمهایی را که به طور معمول چندین ثانیه یا کسری از ثانیه بین دریافت داده و تولید نتیجه تأخیر دارند، سیستمهای زمان واقعی مینامند.

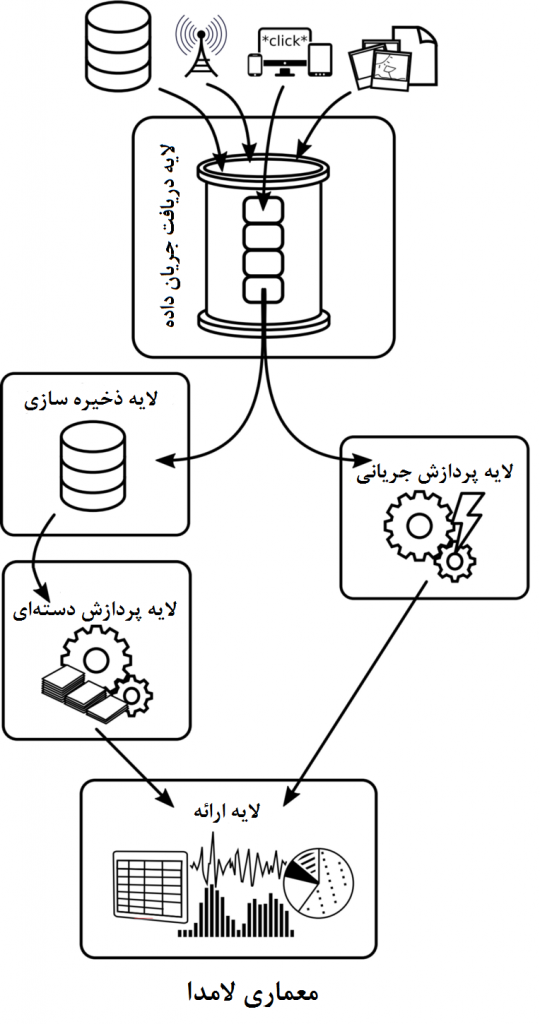
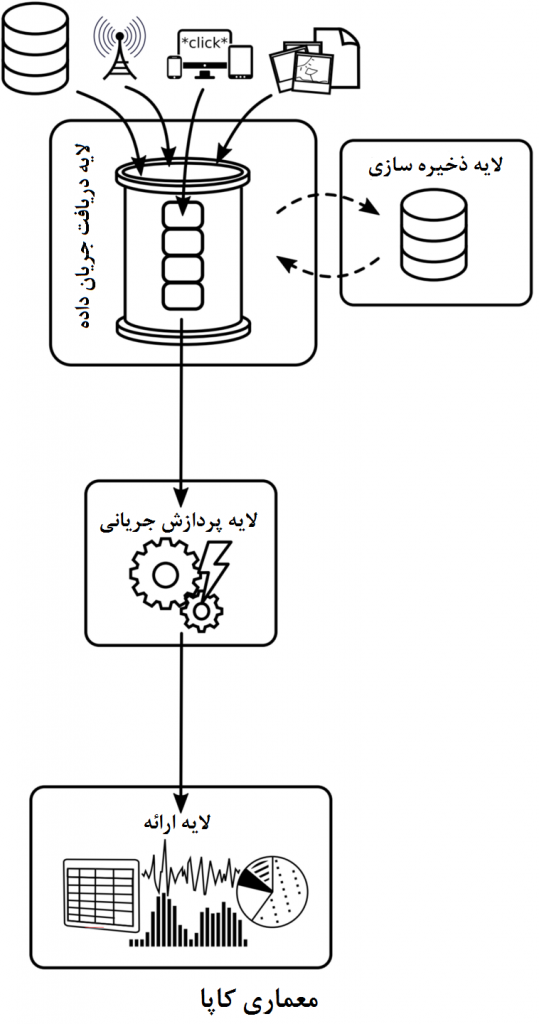
با وجود این، بخشهای عظیمی از زیرساخت کلانداده در حال حاضر از اجزای توزیع شده ساخته شدهاند که از طریق شبکههای غیرهمزمان با یکدیگر ارتباط برقرار میکنند و اکثر این مولفهها بر روی ماشین مجازی جاوا (JVM) طراحی شدهاند. در نتیجه، این سیستمها، سیستمهای زمان واقعیِ نرم هستند و هیچگاه کران بالای دقیقی از مدت زمان تولید خروجی نخواهند داد. شکل بالا، لایههای معمول خطلوله تجزیه و تحلیل جریانی دادهها را نمایش میدهد. دادههایی مانند کلیکهای کاربران، اطلاعات پرداخت آنها و یا محتوای غیرساختاریافته مانند تصاویر و یا پیامهای متنی از بخشهای مختلف یک سازمان جمعآوری میشوند و به لایه تحلیل جریانی داده منتقل میشوند (برای مثال سیستمهای مبتنی بر صف مانند Kafka، Kinesis یا ZeroMQ) که از آنجا به پردازشگر جریانی دسترسی دارند و وظایف مشخصی برای تولید خروجی انجام میدهد. این خروجی به لایه ارائه نتایج انتقال داده میشود که میتواند برای مثال واسط کاربری گرافیکی تحت وب تحلیلی مانند موضوعات روز در توئیتر باشد و یا به عنوان دادههای نتیجه تحلیل دریک پایگاهداده نگهداری شود.
در تلاش برای ترکیب کردن هر دو حالت (پردازش دستهای و جریانی)، الگوی معماری با نام معماری لامدا ارائه شده است که برای رفع مشکل کندی پردازشهای دستهای، لایه پردازش دادههای جریانی را به عنوان مکمل، به آن اضافه کرده و درنتیجه هم بعد حجم و هم بعد سرعت در چالشهای کلانداده را به صورت همزمان مورد هدف قرار داده است. معماری لامدا توسط نیتن مارز توسعه دهنده Apche Storm و در کتاب وی، معرفی شد. همانطور که در شکل نشان داده شده، معماری لامدا سیستمی متشکل از سه لایه است: دادهها در لایهای ذخیرهسازی در ابزاری مانند HDFS ذخیره میشود، که از آنجا متناوباً (برای مثال یکبار در روز) به لایه پردزاش دستهای انتقال داده و پردازش میشوند. لایه پردازش جریانی نیز به بخشی از داده که توسط لایه دستهای پردازش نشده میپردازد، و لایه ارائه خروجیهای لایه دستهای و لایه پردازش جریانی را ادغام میکند. مزیت آشکار داشتن یک موتور پردازش جریانی برای جبران تأخیر بالای لایه پردازش دستهای، با پیچیده شدن سیستم در هنگام توسعه، پیادهسازی و نگهداری آن آشکار میشود. اگر لایه پردزاش دستهای توسط ابزاری که از پردازش دستهای و جریانی به صورت همزمان پشتیبانی میکند، (مانند اسپارک) پیادهسازی شود، لایه پردازش جریانی میتواند با استفاده از APIهای جریانی متناظر با آن (مانند مولفه Streaming اسپارک)، با حداقل سربار پیادهسازی شود، تا از منطق کسبوکار و پیادهسازی موجود استفاده شود. اما، برای سیستمهای مبتنی بر هدوپ(نظیر موتور پردازشی نگاشت/کاهش) یا سیستمهای دیگری که API جریانی ارائه نمیدهند، لایه پردازش جریانی تنها به عنوان سیستمی جداگانه در دسترس است. با استفاده از زبانهای انتزاعی مانند Summingbird که محققان توییتر توسعه دادهاند برای نوشتن منطق کسبوکار، امکان کامپایل خودکار کد برای سیستمهای پردازش دستهای و جریانی (مانند نگاشت/کاهش و استورم) فراهم میشود و در نتیجه توسعه را در مواردی که لایه پردزاش دستهای و جریانی میتوانند از (بخشهایی از) منطق کسبوکار یکسان استفاده کنند، سهولت میبخشد اما سربار پیادهسازی و نگهداری همچنان باقی میماند.
در رویکرد دیگری به نام معماری کاپا، که در شکل مقابل نشان داده شدهاست، برخلاف حالت پیشین، لایه دستهای را برای سادهسازی کنار میگذاریم. ایده اصلی این معماری به این صورت است که تمام دادهها متناوبأ در لایه دستهای پردازش نمیشود و تمام پردازشها به تنهایی در لایه پردازش جریانی صورت میگیرد و تنها زمانی پردازش دوباره انجام میشود، که منطق کسبوکار با پردازش مجدد دادههای قدیمی، تغییر یابد. برای این منظور، معماری کاپا از توانایی یک موتور پردزاشی قدرتمند جریانی، که بتواند از عهده پردازش دادهها با نرخی بیشتر از سرعت ورودشان برآید، استفاده میکند و از یک سیستم جریانی مقیاسپذیر، برای نگهداری داده بهره میگیرد. یکی از مثالهای چنین سیستمی، ابزار آپاچی کافکا است که به صورت خاص برای کار با ابزارهای جریانی با این نوع معماری طراحی شده است و در این معماری ابزار بسیار مطلوبی است. ذخیره داده (برای مثال در HDFS) همچنان امکانپذیر است، اما معمولاً به دلیل پشتیبانی از نگهداری چندین هفتهای داده در کافکا الزامی نیست. اما موضوع نامطلوبی که در اینباره میتواند وجود داشته باشد، تلاشی است که ممکن است برای بازپخش تاریخچه صرف میشود و به صورت خطی با افزایش حجم داده افزایش مییابد. رویکرد نگهداری تمام تغییرات جریان، میتواند الزاماتی سنگینتر از ذخیرهسازی داده، مانند پردازش متناوب دادههای جدید و بهروزرسانی پایگاهدادههای موجود (بسته به اینکه دادهها تا چه اندازه بصورت مؤثر در لایه جریان متراکم شدهاند) تحمیل کند. در نتیجه، معماری کاپا تنها در کاربردهایی به عنوان جایگزین لامدا مطرح میشود، که نیازی به زمان نگهداری نامحدود نباشد و یا اجازه متراکم کردن مؤثر وجود داشته باشد (به عنوان مثال، زمانیکه منطقی است تنها جدیدترین مقدار برای هر کلید و یا موجودیت در برنامه نگهداری شود).
البته، تأخیر موجود در لایه پردازش جریانی تنها کسری از تأخیر برنامه است. تاخیر برنامه میتواند بر اثر ارتباطات شبکه یا ابزارهای دیگر موجود در خطلوله باشد. اما مسلماً معیاری حائز اهمیت است و میتواند معین کند که کدام ابزار، در کاربردهایی با زمانبندی تعیینشده در توافقنامه سطح خدمات، انتخاب شود. در این مقاله بر روی سیستمهای موجود در لایه پردازش جریانی تمرکز خواهیم داشت.
پردازشگرهای جریانی
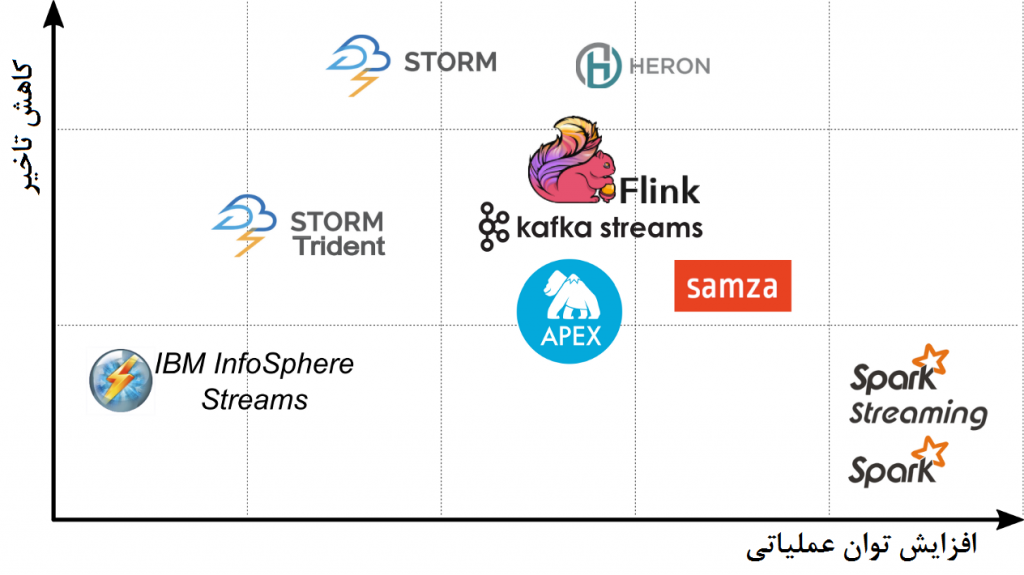
در حالی که تمام موتورهای پردازشگر جریانی مشابهتهایی در مفاهیم اساسی و اصول کارکردی دارند و در برخی از زمینهها اشتراکاتی نیز دارند، اما در بین این سیستمها، تمایز مهمی که مستقیماً بر روی زمان پردازش قابل حصول (به عبارت دیگر تأخیر) تاثیر دارد نیز وجود دارد. این تمایز مدل و رویکرد پردازشی است که در این ابزارها بکار گرفته شده است. در شکل زیر این وجه تمایز نشان داده شده است. در موتورهای پردزاشی جریانی، دادهها بلافاصله پس از رسیدن بررسی میشوند و به بهای افزایش سربار به ازای هر آیتم داده (برای مثال از طریق پیامرسانی)، تأخیر را کاهش میدهند. در حالیکه در سیستمهای دستهای، بافر کردن و پردازش دادهها در دستهها کارایی را افزایش میدهد، اما مسلماً زمانی که هر آیتم داده در خطلوله صرف میکند را افزایش میدهد. ابزارهای صرفاً جریانی مانند Strom، تأخیر بسیار کم و هزینه نسبتاً بالا به ازای هر آیتم داده ارائه میدهند، در حالیکه سیستمهای مبتی بر پردازش صرفاً دستهای با وجود تأخیر زیاد، کارایی بی نظیر در استفاده از منابع دارند و دارای تأخیری هستند که در کاربردهای جریانی و زمان واقعی بسیار بالا است.

فضای بین این دو دیدگاه افراطی بسیار وسیع است و بعضی سیستمها مانند چهارچوب Trident در Storm و Streaming درSpark از استراتژیهای میکرو-دستهای استفاده میکنند تا بین تأخیر و توان عملیاتی توازنی بدست آورند: تریدنت، با گروهبندی تاپلها در دستهها، از مدل پردازشی لحظهای آیتمها کاسته و توان عملیاتی را افزایش میدهد، در حالی که اسپارک استریمینگ اندازه دسته را بر اساس مدت زمان در هنگام پردازش آیتمهای داده مشخص میکند، تا تأخیر را کاهش دهد. در ادامه، به تفضیل برخی از ویژگیهای این ابزارهای محبوب را بررسی میکنیم و درباره تصمیمات در مورد طراحی و انتخاب آنها بحث میکنیم.
Apache Storm
استورم از سال ۲۰۱۰ در حال توسعه است، و در سپتامبر ۲۰۱۱ توسط توئیتر به صورت متنباز منتشر شد و نهایتاً در سال ۲۰۱۴ به صورت پروژهای سطح بالا در آپاچی درآمد. استورم اولین موتور پردازشی جریانی توزیع شده بود که پس از تحقیقات و بهکارگیری مورد توجه قرار گرفت و ابتدا به عنوان «هدوپ بلادرنگ» ترویج یافت، زیرا مدل برنامهنویسی ارائه شده توسط آن، مشابه الگوی نگاشت/کاهش که از پردازش دستهای انتزاع یافته، از پردازش جریانی تفکیک شده است. اما گذشته از اینکه استورم جز اولین ابزارهای پردازش دادههای جریانی است، این ابزار همچنین به خاطر سازگاریاش با اکثر زبانهای برنامه نویسی، طیف وسیعی از کاربران را داراست. همچنین علاوه بر APIهای جاوا، استورم با پروتکل Thrift نیز سازگار است و مجموعهای از آداپتورهایی در چندین زبان، مثل Perl، Python و Ruby دارد. استورم میتواند بصورت کلاستر و یا یک ماشین واحد، بر روی ابزارهای مدیریت منابع کلاستر نظیر Mesos، Yarn و یا با پیکربندی آن بدون استفاده از این ابزارها مستقر شود.
بخشهای الزامی برای پیادهسازی استورم عبارتند از: یک کلاستر ZooKeeper برای ایجاد هماهنگی و ایجاد ویژگی قابلیت اطمینان، چندین پروسه Supervisor برای اجرا (به عنوان Worker) و یک سرور Nimbus برای توزیع کد در کلاستر و انجام اقدامات مناسب هنگام از کار افتادن گرههای worker. به منظور پشتیبانی از قابلیت ایجاد دسترسپذیری وبرای مقابله با از کار افتادن سرور Nimbus، استورم اجازه حضور چندین جانشین از Nimbus را میدهد. استورم دارای ویژگیهای مقیاسپذیری و تحملپذیری در برابر خطاست و حتی در صورت واگذاری مجدد کار در زمان اجرا، رفتاری کشسان خواهد داشت. از نسخه ۱٫۰٫۰، استورم پیادهسازی حالت قابل اطمینان در کلاستر را ارائه داده است که این ویژگی به معنای آن است که در صورت شکست و از کار افتادن یک supervisor، برنامه بتواند به عملکرد خود ادامه داده و آن قسمت از کار را که از دست داده دوباره بازیابی کند.
نسخههای قدیمیتر استورم بر روی پردازش بدونحالت تمرکز داشتند و در نتیجه توسعه دهندگان برنامه در سطح برنامه نیاز بود به مدیریت حالت بپردازند تا در کاربردهایی که نیاز به نگهداری حالت برای بدست آوردن ویژگیهای تحملپذیری خطا و کشسانی بودن دارند، دستیابند. استورم سرعتی بینظیر دارد و در نتیجه میتواند عملکردی در حدود چند میلیثانیه در کاربردهای خاص داشته باشد. البته، به دلیل تأثیرات تأخیر شبکه و فرایند GC ،در توپولوژیهای واقعی همیشه تأخیر نهایی(end-to-end) کمتر از ۵۰ میلیثانیه نخواهد بود.
برنامه یا خطلوله داده در استورم، توپولوژی نامیده میشود و همانطور که در شکل نشان داده شده، گرافی جهتدار است که جریان داده را به صورت یالهای جهتدار و هر عملگر پردازشی را به صورت یک گره نشان میدهد. گرههایی که جریان داده را به داخل منتقل کرده و در نتیجه جریان داده را در داخل توپولوژی آغاز میکنند، Spout نامیده میشوند و آن گرههایی که تاپلهای داده را به گرههای پایین جریان هدایت میکنند و همچنین منطق برنامه را پیادهسازی میکنند، Bolt نامیده میشوند. Boltها میتوانند دادههای تولید شده را بر روی حافظه خارجی بنویسند و یا ممکن است تاپلها را دوباره به گرههای پایینتر خودشان ارسال کنند. استورم دارای چندین گروهبندی است که جریان داده را بین گرهها کنترل میکند، برای مثال، با بر هم زدن و یا پارتیشنبندی مبتنی بر توابع درهم، جریانی از تاپلها را براساس مقادیر بعضی از ویژگیهای آنها گروهبندی میکند، و همچنین کاربر نیز میتواند بر اساس منطق کسبوکار خود، قوانین گروهبندی را با پیادهسازی برخی از کلاسهای استورم، اعمال کند. به صورت پیشفرض، استورم گرههای Spout و Bolt را بین گرههای یک کلاستر به شکل گردشی توزیع میکند،. هرچند این الگوریتم زمانبندی نیز قابل جابجایی است تا در مواردی که در آن گره خاصی (مثلاً به دلیل وابستگیهای سختافزاری) باید مراحل مشخص پردازشی را انجام دهد نیز قابل اجرا باشد. در حالت کلی میتوان گفت منطق برنامه در تعریفی از جریان داده، Spoutها و Boltها کپسوله شده(که به آن توپولوژی میگوییم) تا رابطهایی را برای تعریف رفتار برنامه در هنگام راه اندازی برنامه، دریافت جریان داده یا دریافت تاپلهای داده، پیادهسازی کند.
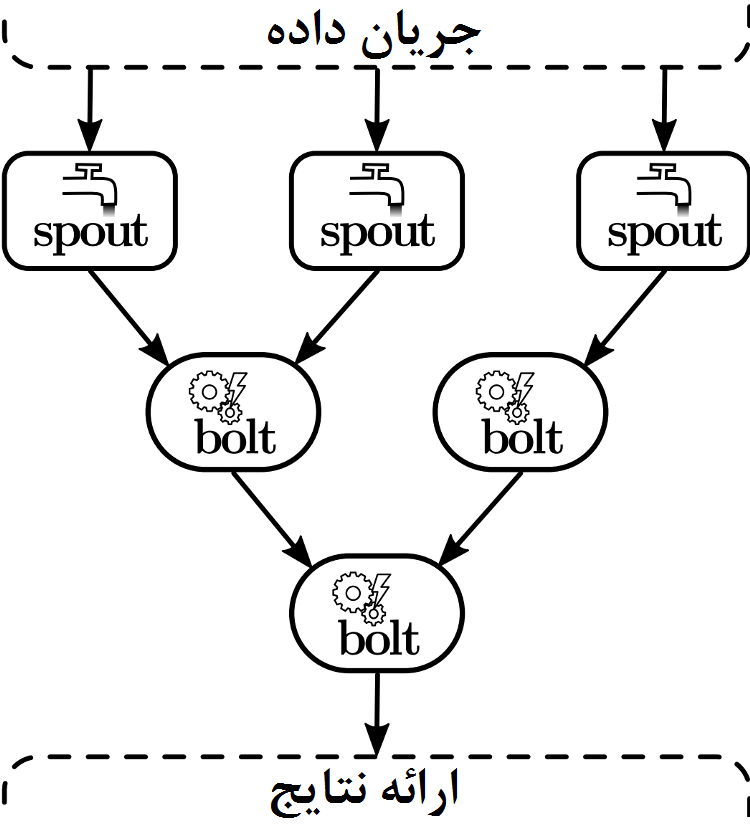
با آنکه استورم هیچ تضمینی در ترتیب پردازش تاپلها ارائه نمیدهد، از طریق ویژگی پیام تصدیق، که وضعیت پردازش هر تاپل در مسیرش در طول توپولوژی را دنبال میکند، حداقل-یکبار-پردازش تاپل را ضمانت میکند به این ترتیب که اگر هر Bolt درگیر در پردازش تاپل، با شکست مواجه شود، یا در دوره زمانی معلوم پیام تصدیق موفقیت نرسد، استورم آن تاپل را دوباره پردازش میکند. با استفاده از معماری یک سیستم جریانی مناسب، حتی امکان محافظت از Spoutها در برابر شکست نیز وجود دارد، اما ویژگی پیام تصدیق به دلیل سربار تحمیل شده پیامرسانی هر تاپل معمولاً در عمل مورد استفاده قرار نمیگیرد، برای مثال پیگیری رد یک تاپل و تمام تاپلهایی که از طرف Spoutها منتشر شدهاند، سبب افت قابل توجه توان عملیاتی قابل دستیابی توسط سیستم میشود. در نسخه ۱٫۰٫۰، استورم مکانیزم Backpressure را معرفی کرد تا در صورت کمتر بودن سرعت پردازش داده از دریافت داده، جلوی دریافت داده را بگیرد. بدون چنین مکانیزمی در توپولوژی اگر پردازش تبدیل به گلوگاه شود، توان عملیاتی به سبب آنکه تاپلها در نهایت دچار time-out میشوند، کاهش مییابد و به همین سبب آیتمهای داده یا از دست میروند (حداکثر یکبار پردازش میشوند) یا بدلیل ایجاد time-out مکررا پردازش میشوند تا دوباره متوقف شوند (حداقل یکبار پردازش میشوند) و در نتیجه حتی بار بیشتری بر سیستمی که تحتفشار قرار داده وارد میشود.
Storm Trident
در سال ۲۰۱۲ و با نسخه ۰٫۸٫۰ استورم، Trident به عنوان API سطح بالا، با تضمین قویتری در ارائه ترتیب دار دادهها و رابط برنامهنویسی انتزاعیتر، و با پشتیبانی داخلی از عملگرهای پیوند، تجمیع ، گروهبندی، توابع و فیلترها معرفی شد. بر خلاف استورم، توپولوژیهای تریدنت به صورت گرافهای جهتدار غیرمدور (DAG) است، زیرا این چهارچوب از وجود دور در چیدمان مولفهها پشتیبانی نمیکند. به همین دلیل شاید برای پیادهسازی در الگوریتمهای تکرار شونده گزینه مناسبی نباشد و از توپولوژیهای ساده استورم، که به اشتباه به عنوان DAG مطرح میشوند و میتوانند دارای دور باشند، نیز متفاوت است. همچنین، تریدنت بر روی تاپلها به صورت منفرد کار انجام نمیدهد، بلکه از مکانیسم میکرودستهها استفاده میکند و سایز دسته را به عنوان پارامتری معرفی میکند که توان عملیاتی را، در ازای افزایش تأخیر، افزایش میدهد، هرچند تأخیر آن برای دستههای کوچک کماکان چندین میلیثانیه است. به صورت پیشفرض تمام دستهها به صورت متوالی، یکی پس از دیگری، پردازش میشوند، هرچند میتوان تریدنت را طوری پیکربندی کرد که چندین دسته را به صورت موازی پردازش کند. علاوهبر ویژگیهای مقیاسپذیری و کشسانی بودن استورم، تریدنت برای مدیریت حالت تحملپذیری خطا، API خود را با رویکرد پردازشی دقیقاً-یکبار-پردازش ارائه میدهد. در حقیقت، تریدنت با استفاده از ویژگی پیام تصدیق استورم، موجب جلوگیریِ از دست دادن آیتمهای داده میشود و تضمین میکند که با نگهداری اطلاعات اضافی در کنار وضعیت هر تاپل و بهروزرسانی تراکنشی آنها، هر تاپل در حالت ماندگار خواهد بود.
Apache Samza
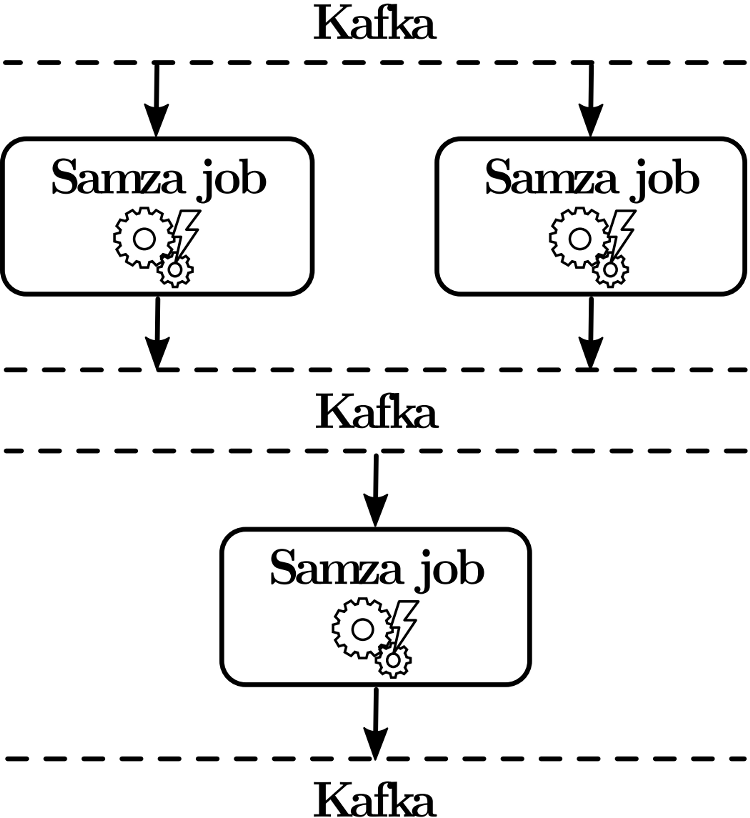
Samza بسیار مشابه استورم است، موتور پردازشی جریانی است که با مدل پردازشی در هر زمان یک آیتم داده (در مقابل با حالت میکرودستهایی) و رویکرد پردازشی حداقل-یکبار-پردازش کار میکند. این ابزار ابتدا توسط لینکدین ایجاد شد و در جولای ۲۰۱۳ به مرکز پروژههای نوپای بنیاد آپاچی ارائه شد و در سال ۲۰۱۵ به عنوان پروژهای سطح بالا در آپاچی شد. Samza به همراه ابزار مدیریت صفکافکا توسعه یافت و در نتیجه پیامرسانی آنها شبیه به یکدیگر هستند: جریان دادهها پارتیشنبندی میشوند و پیامهای (یا آیتمهای داده) داخل هر پارتیشن بصورت مرتب شده ارائه میشوند، اما ترتیبی بین پیامهای پارتیشنهای مختلف وجود ندارد. اگرچه سامزا میتواند با سیستمهای صفبندی دیگری کار کند، اما برای استفاده از تمام قبلیتهای سامزا، باید ازامکانات کافکا استفاده کرد(لازم به ذکر است، که کافکا از سال ۲۰۱۶ دارای کتابخانه پردازش جریانی مشابه سامزا، با نام کافکا استریم است). در مقایسه با استورم، سامزا به کار تقریبا بیشتری برای استقرار نیاز دارد، زیرا نه تنها به کلاستر Zookeeper ، بلکه برای تحملپذیری خطا به YARN نیز نیاز دارد: در اصل، منطق برنامه به عنوان یک job، از طریق کلاینت Samza YARN به کلاستر ارسال شده و پس از آن شروع به کار کرده و بر یک یا چند کانتینر که برنامه بروی آن اجرا میشوند، نظارت میکند. در این سیستم، مقیاسپذیری از طریق اجرای چندین کار Samza در قالب چند تسک موازی به دست میآید که هر کدام از تسکها از یک پارتیشن جداگانه کافکا استفاده میکنند؛ میزان موازی بودن (یا تعداد تسکها) در حین اجرا نمیتواند به صورت پویا افزایش یابد. مشابه کافکا، سامزا بر روی پشتیبانی از زبانهای مبتنی JVM، به خصوص جاوا، تمرکز دارد. برخلاف استورم و تریدنت، سامزا به گونهای طراحی شده تا بتواند تعداد بسیار زیادی حالت را به روشی تحملپذیر در برابر خطا، از طریق نگهداری حالتها در یک پایگاه داده محلی و تکرار بروزرسانی آنها در کافکا، مدیریت کند.. به صورت پیشفرض، سامزا از یک پایگاه داده کلید-مقداری برای این هدف استفاده میکند، اما دیگر موتورهای ذخیرهسازی با امکانات پسوجوی قویتر نیز میتوانند جایگزین شوند.
همانطور که در شکل معماری سازوکار Samza نشان داده شده است، یک کار Samza یک مرحله پردازشی را در خطلوله تجزیه و تحلیل مشخص میکند و در نتیجه تا حدی مشابه با bolt در توپولوژی استورم است. خروجیهای تولید شده توسط یک کار Samza ، همیشه به کافکا فرستاده میشوند که آنها میتوانند به عنوان ورودی دیگر کارها استفاده شوند. این موضوع به روشنی متناقض با استورم است، که دادهها به صورت مستقیم از یک bolt به دیگری ارسال میشوند. اگرچه یک کار Samza یا یک مرحله ثبت دادههای خروجی در کافکا میتواند پیامی را تنها چند میلیثانیهای به تأخیر بیاندازند، اما تأخیرهای جمع شده و تاخیر خطلولههای تجزیه و تحلیل پیچیده متشکل از چندین مرحله پردازشی نهایتاً تأخیر نهایی بالاتری نسبت به پیادهسازیهای مشابه استورم نشان میدهد.
با این حال، این مدل طراحی، مراحل پردازشی مجزا را تجزیه کرده و در نتیجه توسعه را راحت میکند. دیگر مزیت آن، بافر کردن داده بین مراحل پردازش است که نتایج (میانی) را برای بخشهای نامرتبط، برای مثال تیمهای دیگر در یک شرکت، در دسترس قرار میدهد و حتی نیاز به الگوریتمهای backpressure را رفع میکند، زیرا هیچ نقطه آسیبپذیری در جمعشدن دادههای یک کار، بخصوص به صورت موقت، با داشتن یک کلاستر کافکا با سایز کلاستر معقول وجود ندارد. از آنجایی که سامزا پیامها را به ترتیب پردازش کرده و نتایج پردازشی را دائماً در هر قدم ذخیره میکند، قادر به جلوگیری از دست دادن داده با استفاده از checkpointهایی در فرآیند پردازش میباشد و در صورت شکست، تمام دادهها از آن نقطه به بعد را دوباره پردازش میکند؛ در واقع سامزا تضمینی کمتر از حداقل-یکبار-پردازش ارائه نمیدهد، زیرا حتی با عدم تلاش برای رسیدن به این مورد هیچ افزایش عملکردی در اجرای کارهای Samza بوجود نمیآید. همچنین سامزا دارای رویکرد دقیقاً-یکبار-پردازش نیز نمیباشد، اما اجازه میدهد تا مدت زمان checkpointها را پیکربندی کنیم و در نتیجه بر حجم دادههایی که در مواقع خطا ممکن است چندین بار پردازش شوند، برخی کنترلها را انجام دهیم.
Spark Streaming
چارچوب نرمافزاری اسپارک یک چارچوب پردازشی دستهای است، که از آن به عنوان جانشین غیررسمی چهارچوب نگاشت-کاهش یاد میشود، زیرا مزیتهایی در مقایسه با آن ارائه میدهد، که از قابل توجهترین آنها، میتوان به API مختصرتری که منطق نرمافزاری جمعوجورتر را ارائه میدهد و همچنین بهبود چشمگیر عملکردی از طریق کَشکردن داده در حافظه را اشاره کرد. به طور خاص، اجرای الگوریتمهای تکرارشونده (برای مثال الگوریتمهای یادگیری ماشین مانند خوشهبندی k-means یا رگرسیون لجستیک) با کارایی بسیار بیشتری (تا حدود ۱۰۰ برابر) محقق میشود، زیرا دادهها الزاماً در بین مراحل پردازشی بر روی دیسک نوشته و از روی آن خوانده نمیشود. علاوه بر این مزیتهای عملکردی، اسپارک مجموعهای از الگوریتمهای یادگیری ماشین آماده استفاده را از طریق کتابخانه MLlib و پشتیبانی از بسیاری از عملکردهایSQL را از طریق مولفه Spark Sql ارائه میدهد. اسپارک در سال ۲۰۰۹ در آزمایشگاه AMP برکلی آغاز به کار کرد، و در ۲۰۱۰ به صورت متن باز منتشر شد و در ۲۰۱۳ به بنیاد نرمافزاری آپاچی واگذار شد که در آنجا در فوریه ۲۰۱۴ به صورت پروژهای سطح بالا در آمد. عمدتاً به زبان اسکالا نوشته شده و API جاوا، اسکالا و پایتون دارد و از زبان R نیز پشتیبانی میکند. مفهوم اصلی در اسپارک، مجموعههای توزیع شده و تغییرناپذیر به نام RDD است که میتوانند از طریق عملگرهای Transformation و Action تغییر پیدا کنند. اسپارک در برابر شکست با داشتن ریشه دنباله RDDها مقاوم است (به عبارت دیگر با دانستن ترتیب عملگرهایی که آن را ایجاد کرده، و ثبت RDDهایی که پردازش دوباره آنها هزینهبر است). استقرار اسپارک شامل یک مدیر کلاستر برای مدیریت منابع و نظارت بر آن، یک درایور برنامه برای زمانبندی برنامه و تعدادی گره worker برای اجرای منطق برنامه است. کلاستر اسپارک را میتوان توسط ابزارهای Mesos، YARN یا به صورت Standalone (ابزار مدیریت کلاستر موجود در اسپارک که دارای معماری Master/Slave میباشد که میتوان از ابزار ZooKeeper برای مقابله با (SPOF) شکست گره master نیز استفاده کرد) مستقر کرد.
مولفه Streaming اسپارک، از طریق تقسیمبندی جریان ورودی داده به دستههای کوچک، و تبدیل آنها به RDDها و پردازش آنها به صورت معمول، رویکرد پردازش دستهای را به سمت شرایط زمان واقعی و جریانی تغییر میدهد و پس از آن به جریان داده و توزیع خودکار آن میپردازد. از اواخر ۲۰۱۱ اسپارک استریمینگ در حال توسعه است و از فوریه ۲۰۱۳ به عنوان بخشی از اسپارک درآمده است. به همین دلیل، جامعه بزرگی از توسعهدهندگان و جمع زیادی از کاربران را از ابتدا بهمراه داشته، زیرا هر دو سیستم از API مشترکی استفاده میکنند و مولفه Streaming بر روی کلاستر معمول اسپارک نیز اجرا میشود. بدین ترتیب، مولفه Streaming میتواند مانند Strom و Samza نسبت به شکست اجزا خود مقاوم باشد و از مقیاسپذیری پویا منابع اختصاص یافته به برنامه پشتیبانی کند.
دادههای دریافت شده قبل از پردازش از طریق گرههای worker به صورت دنبالهای از RDDها، بنام DStream تبدیل میشوند. تمام RDDهای داخل DStream به ترتیب پردازش میشوند، درحالیکه دادهها در داخل RDDها به صورت موازی(در حالت کلی و در هسته اسپارک)، بدون ترتیب مشخصی، پردازش میشوند. از آنجایی که زمانبندی کار تأخیر مشخصی هنگام پردازش RDD ایجاد میکند، دستههای با اندازه کمتر از ۵۰ میلیثانیه غیرقابل اجرا هستند. بر این اساس، در بهترین شرایط پردازش یک RDD حدود ۱۰۰ میلیثانیه طول میکشد، با وجود اینکه مولفه Streaming اسپارک با تأخیری در مقیاس چند ثانیه طراحی شده است. برای جلوگیری از دست دادن داده حتی برای منابع غیرقابلاطمینان، اسپارک استریمیگ از تکنیک WAL استفاده میکند، که از طریق آن میتوان داده را بعد از شکست دوباره بازیابی و پردازش کرد. مدیریت حالت در این چهارچوب از طریق مدیریت حالت در DStreamها ممکن شده است، که میتواند از طریق عملگرهای Transformation بروی DStreamها بهروزرسانی شود.
Apche Flink
آپاچی فلینک پروژهای همجهت با اسپارک استریمینگ است. تحقیقات و تبلیغات آن بر هماهنگی پردازش دستهای و جریانی در یک سیستم تاکید دارد، و تضمین تنها-یکبار-پردازش برای مدل برنامهنویسی جریانی و API قابل قیاس با Trident ارائه میدهد. فلینک ابتدا با نام Stratosphere شناخته میشد، اما از اواسط ۲۰۱۴ با نام کنونیاش شناخته میشود و در مارچ ۲۰۱۶ نسخه ۱٫۰٫۰ آن قابل دسترس شد. برخلاف Spark Streaming، پروژه فلینک بصورت بنیادی یک پردازشگر جریانی است و بر پردازش دستهای تکیه ندارد. در کنار APIهای دستهای و APIهای جریانی(که تمرکز این مقاله بر روی آن است)، فلینک APIهایی برای پردازش گراف، پردازش رویدادهای پیچیده (CEP) و SQL ارائه میدهد و قادر به اجرا تپولوژی استورم نیز است. فلینک میتواند با استفاده یکی از سیستمهای مدیریت منابع مانند YARN یا Mesos، یا به صورت standalone مستقیماً بر روی ماشینها مستقر شود. پیادهسازی فلینک حداقل به یک فرآیند JobManager (با جایگزین اختیاری در صورت بروز شکست) برای هماهنگی checkpoint ها و بازیابیها و دریافت یک job نیاز دارد. JobManager همچنین وظایف را بین فرآیندهای TaskManager ، که معمولاً بر روی ماشینی جداگانه قرار میگیرد و کدها را به ترتیب اجرا میکند، زمانبندی میکند
از نظر مفهومی، فلینک را میتوان به عنوان یکی از پیشرفتهترین پردازشگرهای جریانی در نظر گرفت، زیرا بسیاری از ویژگیهای اصلیاش که در طراحی اولیه در نظر گرفته شده بود، بعد از در نظر گرفتن جوانب دیگر، اضافه نشد(به عنوان مثال برخلاف API جریانی اسپارک یا مدیریت حالت استورم که بعد از توسعه هسته پروژه بوجود آمدند). برای تضمین پردازش دقیقاً-یکبار، فلینک از الگوریتمی براساس الگوریتم Chandy-Lamport برای snapshotهای توزیع شده استفاده میکند. از اینرو آیتمهای واترمارک مرتباً به جریان داده تزریق میشوند و موجب میشوند که هر جزء دریافت شده، یک نقطه Checkpoint از حالت محلیاش ایجاد کند. به این ترتیب، تمامی نقاط Checkpoint برای یک واترمارک، نقطه وارسی سراسری سیستم توزیع شده را تشکیل میدهند. در مواردی که شکست رخ میدهد، تمامی اجزا به آخرین نقطه Checkpoint سراسری بازگردانی میشوند و دادهها از واترمارک مربوطه پردازش میشوند. از آنجایی که آیتمهای داده ممکن است هیچوقت از واترمارک آیتمها بیشتر نشود، ارسال پیام تصدیق برای هر آیتم صورت نمیگیرد و در نتیجه نسبت به استورم سبکتر است. فلینک از مکانیزم backpressure با استفاده از بافر با ظرفیت محدود استفاده میکند: هر زمانی که دریافت داده از سرعت پردازش بیشتر شود، بافرهای داده مانند صفهای مصدود کننده با سایز ثابت رفتار میکنند و در نتیجه نرخی که دادههای جدید به سیستم وارد میشود را کند میکند. با قابلیت تنظیم کردن زمان بافردهی برای آیتمهای داده در فلینک، میتوان توازن بین تأخیر و توان عملیاتی کنترل کرد و میتوانید توان عملیاتی بالاتری نسبت به استورم داشته باشید.
راهنمایی در تصمیمگیری
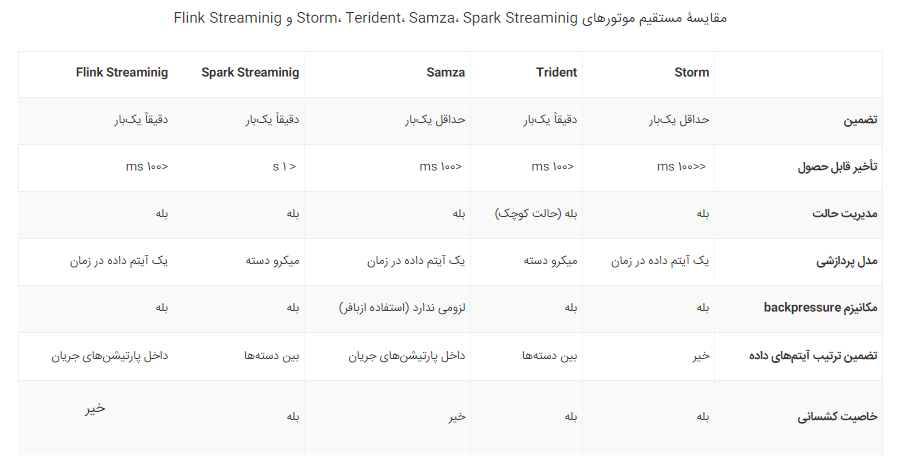
در جدول زیر، ویژگیهای سیستمهای بحث شده در بالا را مقایسه میکنیم. استورم کمترین تأخیر را ارائه میدهد، اما ترتیب آیتمهای داده را تضمین نمیکند و معمولاً بدون تضمین دریافت، پیادهسازی میشود، زیرا پیام تصدیق برای هر تاپل که برای پردازش-حداقل-یکبار نیاز است باعث دو برابر شدن سربار ارسال پیام میشود. Trident از طریق بهروزرسانیهای حالتهای تکرارشونده، پردازش -دقیقا-یکبار را فراهم میکند، اما این ویژگی تأثیر چشمگیری بر روی کارآیی و حتی تحملپذیری خطا در برخی موارد شکست دارد. Samza یکی دیگر از پردازشگرهای اصلی است که اندازه استورم دارای تأخیر کم نیست و بیشتر بر روی سمنتیک غنی تر، به طور خاص از طریق مفهوم مدیریت حالت تمرکز میکند. این سیستم برای کار به همراه کافکا در معماری کاپا توسعه یافته، و Samza و کافکا همبستگی تنگاتنگی با یکدیگر دارند و سمنتیک ارسال پیام مشترکی دارند، در نتیجه، Samza میتواند از تضمینهای مرتبسازی کافکا به طور کامل بهره ببرد. Spark Streaming و Flink به صورت مؤثری پردازش دستهای و جریانی را کنار هم (البته از جهات متفاوت) قرار میدهند، و APIهای سطح بالا، تضمین پردازش–دقیقا-یکبار و مجموعهای از کتابخانههای مفید را ارائه میدهند، که همگی میتوانند پیچیدگیهای توسعه نرمافزار را به شدت کاهش دهند. اکوسیستم اسپارک بدون شک دارای بیشترین حجم کاربر و توسعهدهنده است، اما به دلیل اینکه رویکرد آن مدل پردازشگر دستهای است، Spark Streaming در میزان تأخیر تسلیم رقیبانش شده است. فلینک با طراحیای که دارد، محدودیتهای جدی نداشته اما هنوز به صورت همهگیر مورد استفاده قرار نگرفته است.
این سیستمهای متنوع نشان میدهند که تأخیر کم با پارامترهای مطلوب دیگری مثل توان عملیاتی، تحملپذیری خطا، قابلیت اطمینان (تضمین پردازش) و راحتی توسعه باید در توازن باشد. توان عملیاتی میتواند با بافر کردن داده و پردازش آن به صورت دستهای بهینه شود تا تاثیر ارسال پیام و دیگر سربارهای هر آیتم داده کاهش یابد، درحالیکه این موضوع زمان انتظار هر آیتم داده را افزایش میدهد. رابطهای انتزاعی، پیچیدگیهای سیستم را مخفی میکنند و روند توسعه نرمافزار را راحتتر میکنند، اما گاهی سبب محدود شدن امکان تنظیم برای رسیدن به کارایی مطلوب میشوند. به صورت مشابه، تضمینهای پردازشی و تحملپذیری خطا در بهرهبرداریهای Statefull، قابلیت اطمینان را افزایش میدهند و پیادهسازی مدلهای متفاوت (دقیقا-یکبار-پردازش، حداقل-یکبار-پردازش و …) را راحتتر میکند، اما نیازمند کارهای اضافی برای سیستم، نظیر پیام تصدیق و تکرار (همزمان) وضعیت هستند. مدلهای پردازشی دقیقاً-یکبار بسیار مطلوب هستند و میتوانند از ترکیب تضمین حداقل-یکبار به همراه بهروزرسانیهای تراکنشی یا تکرار شونده Stateها بدست آیند.
__________________________________________________
منبع : datastack.ir