persian
persian") English (UK)
English (UK) 
آپاچی تیکا:
آپاچی تیکا یکی از پروژههای متن باز Apache است که کلاسی برای شناسایی زبان متون دارد. Tika برای استخراج متن اصلی از فایل های متنی و تجزیه کردن قسمت های مختلف فایل با توجه به متا دیتای آن کاربرد دارد. تیکا برای تعیین زبان یک متن، میزان فاصله بازنمایی آن متن را با بازنمایی زبانهای موجود در سیستم تعیین میکند و زبانی که کمترین فاصله را با متن موجود دارد، در صورت رسیدن به یک اطمینان نسبی از زبان شناسایی شده، آن زبان را بر میگرداند. فاصله بین متن موجود و زبانهای مختلف برمبنای فاصله اقلیدسیِ بسامد نسبی n-gramهای (یعنی نسبت بسامد هر n-gram به مجموع بسامد n-gramهای موجود) واقع در بازنمایی متن و بازنمایی زبان، محاسبه میشود. جویشگر متنباز Nutch نیز برای شناسایی زبان صفحات از Tika استفاده میکند
 آپاچی تیکا
آپاچی تیکا
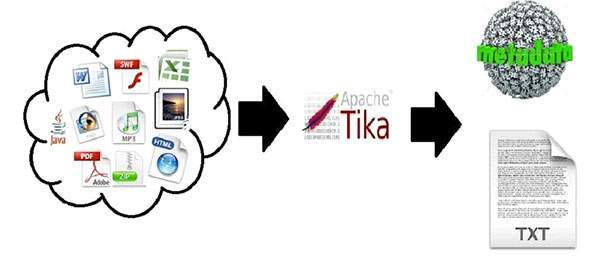
ابزار ابزاری Apache Tika ™ می تواند متادیتا و متن را از بیش از هزار نوع فایل مختلف (مانند PPT، XLS و PDF) شناسایی و استخراج کند. همه این انواع فایل ها را می توان از طریق یک رابط واحد تجزیه کرد، که Tika برای نمایه سازی موتورهای جستجو، تجزیه و تحلیل محتوا، ترجمه و غیره مفید است. شما می توانید آخرین نسخه را در صفحه دانلود پیدا کنید. لطفا برای دریافت اطلاعات بیشتر در مورد نحوه شروع استفاده از Tika صفحه شروع به کار را مشاهده کنید.
صفحات پارس و آشکارساز اصلی رابطهای Tika و نحوه کار آنها را توضیح می دهند. اگر شما علاقه مند به مشارکت در Tika هستید، لطفا به صفحه Contributing مراجعه کنید یا یک ایمیل به لیست توسعه Tika ارسال کنید.
Tika یک پروژه از بنیاد نرمافزار آپاچی است و قبلا یک زیر پروژه آپاچی لوسیان بود.
Tika برای شناسایی زبان سندها از یک فایل tika.language.properties استفاده میکند که شامل اسامی دو حرفی زبانها بر مبنای استاندارد ISO 639 است. بر مبنای این فایل، مجموعهای از فایلهای Language Profile مربوط به زبانهای اشاره شده در tika.language.properties از حافظه جانبی خوانده میشوند و برای ساخت pofileهای زبانی مورد استفاده توسط Tika به کار گرفته میشوند. نام فایل های Language Profile به شکل <Language>.ngp است و شامل مجموعهای از n-gramهای حرفی به همراه فراوانی آنها برای یک زبان است. بخشی از فایل en.ngp که مربوط به زبان انگلیسی است در ادامه آورده شده است.
# See the License for the specific language governing permissions and
# limitations under the License.
_th 154732
the 117027
he_ 95427
on_ 52529
ion 52199
_in 48458
_of 47302
_to 46961
با مقایسهی این n-gramها و n-gramهای استخراج شده از متن یک صفحه HTML مورد بررسی، میزان شباهت زبان متن صفحه با هر یک از زبانهای موجود در Tika تعیین میشود. بر اساس یک مقدار از پیش تعیین شده برای ReasonablyCertain بودن برای زبان تشخیص داده شده، زبان شناسایی شده یا مقدار null بازگردانده میشود.
کلاس LanguageIdentifier در Tika برای تعیین زبان متن، میزان فاصله content profile آن متن را (که مشابه با Language Profile یک زبان است) با Language Profile زبانهای موجود در Tika تعیین میکند و زبانی که کمترین فاصله را با متن موجود دارد، در صورت رسیدن به یک اطمینان نسبی از زبان شناسایی شده، برمیگرداند. فاصله بین متن موجود و زبانهای مختلف برمبنای فاصله اقلیدسیِ بسامد نسبی n-gramهای (یعنی نسبت بسامد هر n-gram به مجموع بسامد n-gramهای موجود) واقع در profile متن و profile زبان، محاسبه میشود.
public static String parseToPlainText(String filePath) { //If Your document contained more than 100000 characters, Set writeLimit to (-1) For receive the full text of the document. BodyContentHandler handler = new BodyContentHandler(-1); AutoDetectParser parser = new AutoDetectParser(); Metadata metadata = new Metadata(); try (FileInputStream stream = new FileInputStream(filePath)){ parser.parse(stream, handler, metadata); return handler.toString(); } catch (org.xml.sax.SAXException | IOException | TikaException ex) { JOptionPane.showMessageDialog(null, ex.getMessage(), "Exception in: MyTikaParser-parsToPlainText()", JOptionPane.ERROR_MESSAGE); } return null; }
public static String identifyLanguage(String text) { LanguageIdentifier identifier = new LanguageIdentifier(text);; if (identifier.getLanguage().equalsIgnoreCase("fa")){ if (text.contains("گ") || text.contains("چ") || text.contains("پ") || text.contains("ژ")){ return "fa"; } else { return "ar"; } }else { return identifier.getLanguage(); }
-------------------------------------------------------
منبع: https://tika.apache.org , http://bigdata-ir.com