jHazm نسخه جاوایی هضم از کتابخانه پایتون برای پردازش زبان فارسی است. کتابخانه HAZM برای انجام پردازش های لازم بر روی زبان فارسی توسط دانشجویان دانشگاه علم و صنعت در سال ۱۳۹۲ به صورت متن باز و با استفاده از کتابخانه NLTK منتشر شد. لایسنس این ابزار MIT میباشد. هضم، ابتدا برای زبان پایتون و بر روی سیستم عامل لینوکس طراحی شد ولی بعدها توسط تیم توسعه دهنده برای زبان جاوا و C# نیز بازطراحی شد. با توجه به این که نسخه Jhazm با زبان برنامه نویسی جاوا توسعه داده شده است قابلیت استفاده از آن در پلتفرم ها وجود دارد. تمیز و مرتب کردن متن، جداسازی جملهها و واژهها، ریشهیابی، تحلیل صرفی جمله، تجزیه نحوی جمله و غیره از قابلیتهای هضم است. در زیر عناوین مهم قابلیت های کتابخانه جی هضم آورده شده است.
- تمیز کردن متن (Text cleaning) برای یادگیری normalizer به آموزش نرمال سازی متن با jhazm مراجعه کنید.
- قطعه بند کلمه و جمله (Sentence and word tokenizer)
- ریشه یاب کلمه (Word lemmatizer)
- ماژول بن یاب یا Stemmer
- ماژول StopWord Remover
- برچسب معنایی (POS tagger)
- ماژول کار با عبارات با قاعده RegexPattern
- تجزیه کننده وابستگی (Dependency parser)
- تحلیل صرفی جمله
- تجزیه نحوی جمله
- واسط استفاده از دادههای زبان فارسی
- سازگاری با بسته NLTK
- …
در آینده نزدیک تمام امکانات بالا به مرور آموزش داده خواهد شد.
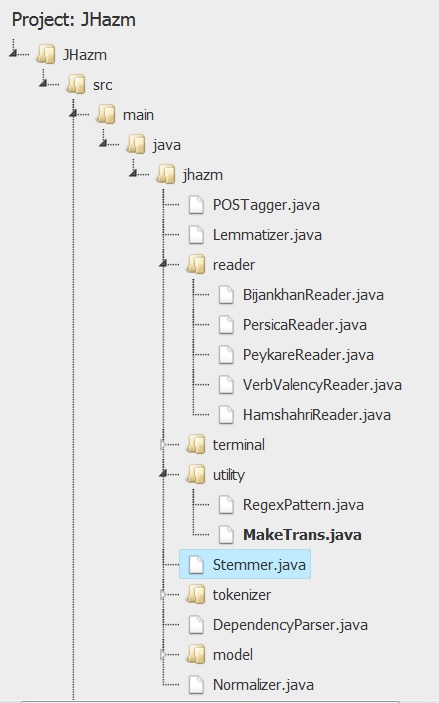


برای پیکره دادگان از منابع زیر استفاده میشود:
نیازمندی ها
- You can download pre-trained tagger and parser models for persian and put these models in the
1JHazm/resources
folder of your project.
برای یادگیری بیشتر ویدئوی زیر را که البته با زبان پایتون است را مشاهده کنید.
---------------------------------------------------
منبع : خانه بیگ دیتای ایران